Event-based server architecture
What's the right way to do multithreading? There's not one single answer to this as every program has it's specific needs and purposes. But on a per-program basis, one approach will probably be better than another.
Game developers not working on high-end engines rarely have to worry much about multithreading. Even if a game is multithreaded, at the core most games' logic is single-threaded.
For instance, if your game has a dedicated rendering thread, your previous frame might be getting rendered while you simulate the current one on the main thread. But what you're doing is you're just replicating the relevant data from the main thread for use by the render thread, thus not affecting the actual game logic, which remains single-threaded.
For another example, your physics system might parallelize a for-loop to multiple threads, all of which are synchronized at the end of the loop. This also does not change your game's logic from single- to multithreaded, you're just iterating some loops faster by parallelizing them.
There's a reason the above two examples are common in games, and it is that they are easy to program for, while getting some of the benefits of dividing work to multiple threads. When all of the real logic happens on a single thread of execution, the control flow is predictable and easy to understand. It might also be more efficient than a truly multithreaded alternative, in case the multithreading is done badly, or the algorithm is not suitable for threading.
Networking and threads
While you can well write a game using just a single thread, writing network code without threads is more difficult. This is because in network programming many blocking calls are used, such as poll() or recvfrom(). Usually, we want a thread to sit there and wait until network messages or new connections arrive. But a sleeping thread cannot do much else, so the other logic must happen on another thread.
It is usually possible to give blocking functions a timeout, so that even if they have no new events to report to us, they will return after a given amount of time. In this way, one can imagine a game-loop-like server architecture that polls for messages and new connections, all the while also executing all of the logic on the same thread as well. With a timed wait, we could have the loop run at approximately, say, 60 FPS.
But servers that want scalability probably don't run on a single thread. I'm no expert of course, so take this with a grain of salt, but so my investigations on the internet suggest. It seems common to have threads dedicated simply to polling for new network events.
State makes things difficult
If the only job of one of our threads, the network thread, is to sleep on poll(), epoll() or similar call and wait for new incoming messages and connections, the logic of the program is handled somewhere else. Instead of interpreting incoming data right there and then on the network thread as it arrives, the interpretation happens on a different thread.
Applications such as game servers use long-lasting connections instead of quickly terminated ones. For long connections, the server has to store some kind of per-client state: the socket of the client, a session id, incomplete messages, game character variables, etc. After acknowledging we have a lot of state, the question becomes: where's the right place to manipulate it, considering our program is multithreaded?
To store the state of our clients we might have a struct called client_t. We also have some kind of a container that contains those structs. Lets say the structs are stored in a pool of a fixed size.
{
int socket;
uint32 session_id;
uint8 unread_messages[512];
int num_bytes_unread;
} client_t;
client_pool_t clients;
/* Returns NULL if no free clients are left in the pool */
client_t *new_client(client_pool_t *pool);
void free_client(client_pool_t *pool, client_t *client);
With the above premise, let's assume our network thread accepts clients and reserves client_t structs for them. If the clients disconnect (recv() returns 0), the network thread frees the client struct.
Now, if all of our connections need to be stored in our global client_pool_t data structure, how do we access it safely from multiple threads? Remember that the network thread does not handle any of the actual (game) logic in the program: that happens elsewhere, and that logic also touches the client structures as it must send messages to the clients or interpret their messages stored in the unread_messages buffer, etc.
The naive answer to safe access is to use a mutex. Wrap the new_client() and free_client() calls to a mutex and you're fine. Now when the network thread accepts a new client, it can safely call new_client() and then somehow signal the main thread that a new client was accepted, passing a pointer to the newly allocated struct along.
There are two problems with this approach: the possible performance concerns, and the (in my opinion) more important topic of code complexity. These problems are somewhat intertwined.
What kind of problems might the above approach lead to? Say that at some point in development you realize that there are situations where, on the main thread, you have to iterate through all of your clients. For that, you might create an array of pointers to the currently used client structs. So now, when you accept a new client and reserve a new client struct from the pool, you have to also push a pointer to the struct to said array.
But now, what might happen is that while the main thread iterates through all of the clients, one of the clients disconnects. In this case the networking thread frees the client struct of the disconnected client. Since we don't want this to happen while we're iterating through the clients, we have to lock the pool's mutex in both cases: while iterating, and while deleting a client.
The possible performance implications of the above are easy understand: the iteration can leave the mutex locked for a while, meaning the networking thread gets blocked until the iteration finishes.
But more importantly, using the above approach we are forced to constantly remind our selves of the fact we can't just go doing anything to our clients on the main thread without remembering the mutex and the possible race conditions. As we add features, the code becomes more and more complicated, and easier to make a mistake at. The above was a simple and somewhat dumb example. For another example, consider what should happen if the networking thread writes recvd() data into a client's unread_messages buffer, and the main thread handles that data. Are you going to use a per-client mutex to protect access to the data buffer while it's getting written to or read from? That's gonna be some more complex code using locks.
To some extent I'm speaking from experience here. When I started writing the MUTA server, I had little clue about how to write a complex server capable of handling a high amount of clients. I'm not sure if I still have the right idea of that, but I know that multithreading was a pain in my ass for a long while, and to some extent it remains so, although I think it's gettin getter.
Handling state on a single thread
So far I've found that the simplest way of dealing with the above woes is to be simple and handle all state changes on on a single thread. No allocations of stateful data structures or otherwise manipulating them from the networking thread or anywhere else. I've referred to this as event-based architecture, but I'm not sure if that's the correct term; all I know is that I've heard the term elsewhere and assumed this was what they meant. Then again, who cares what it's called.
In this model, when a network thread receives a message, it will not handle the message immediately. Instead it will pass it on to another thread as an event. The thread that handles the events (usually the main thread) can sleep on a blocking function from which it wakes when new events are posted from another thread.
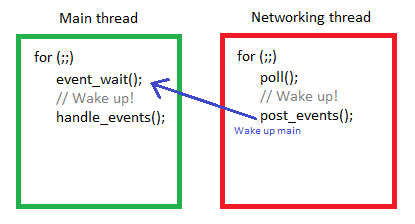
Essentially, both the main and network thread will sleep in this model until something relevant to them happens. Of course, you can have more than one thread pushing events to the main thread though, and you can also have the main thread posting events to other threads. MUTA's login server has a database thread with which the main thread communicates in a two-way fashion, posting and receiving events from it.
Current implementation in MUTA
MUTA's server consists of multiple programs now: the login server, the shard server, the world simulation server, the database server and the proxy server. The two newest applications, the login and proxy servers, implement the architecture described in this post.
The sleeping and waking of a thread is implemented using a condition variable that sleeps on a mutex. The same mutex is locked when items are pushed to the event queue.
The event queue is also a blocking queue. It has a fixed size, and if it fills up, meaning the thread pushing events is pushing them faster than the main thread can handle them, the push function will sleep until space becomes free. This is also implemented using a condition variable.
The event data type of the MUTA login server looks as follow at the moment.
{
EVENT_ACCEPT_CLIENT,
EVENT_READ_CLIENT,
EVENT_ACCOUNT_LOGIN_QUERY_FINISHED,
EVENT_ACCEPT_SHARD,
EVENT_READ_SHARD,
EVENT_LOGIN_REQUEST_RESULT
};
... various event structures ...
struct event_t
{
union
{
int type;
accept_client_event_t accept_client;
read_client_event_t read_client;
account_login_query_finished_event_t account_login_query_finished;
accept_shard_event_t accept_shard;
read_shard_event_t read_shard;
};
};
As an example event, we can take the accept_client event, which is fired when the network thread accept()s a new connection. It looks as follows.
{
int type;
socket_t socket;
addr_t address;
};
As we can see, the event data type is a union. That's because they all get posted into the same array. But what about events that have to transfer variable amounts of data from thread to thread, such as socket recvs() (that is, packets received from the network)? In such cases, we use a simply mutex-locked allocation pool. Lock the allocator's mutex, allocate data, unlock the mutex. At read, we free the allocated memory back to the allocator in a similar fashion.
The allocator used here is a simple segregate fit -type of allocator. The logic is this: on malloc-requests, round up the requested amount to the nearest power of two. Find out the highest (leftmost) bit of the amount and use it as an index into an internal pool of memory blocks of the given size.
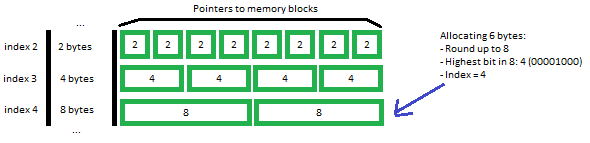
While the allocator calls real malloc when it needs more memory, it has an upper capacity to which it will allocate, since the event queue is blocking. Thus it is not possible to DDOS the server to run out of memory by simply spamming packets at it.
The event API itself looks as follows.
void event_init(event_buf_t *buf, uint32 item_size, int32 max);
void event_push(event_buf_t *buf, void *evs, int32 num);
int event_wait(event_buf_t *buf, void *evs, int32 max, int timeout_ms);
/* -1 as timeout means infinite */
And, using the API, the login server's main loop looks as follows now.
{
event_t events[MAX_EVENTS];
int num_events = event_wait(event_buf, _events, MAX_EVENTS, 500);
for (int i = 0; i < num_events; ++i)
{
event_t *e = &_events[i];
switch (e->type)
{
case EVENT_ACCEPT_CLIENT:
cl_accept(&e->accept_client);
break;
case EVENT_READ_CLIENT:
cl_read(&e->read_client);
break;
case EVENT_ACCOUNT_LOGIN_QUERY_FINISHED:
cl_finish_login_attempt(&e->account_login_query_finished);
break;
case EVENT_ACCEPT_SHARD:
shards_accept(&e->accept_shard);
break;
case EVENT_READ_SHARD:
shards_read(&e->read_shard);
break;
default:
muta_assert(0);
}
}
cl_check_timeouts();
shards_flush(); // Flush queued messages to shards
cl_flush(); // Flush queued messages to clients
}
And so, most logic is handled on a single thread.
Converting other systems to the same approach
The MUTA server's older parts are not implemented using the model discussed in this post. Although they also handle most logic on a single thread based on events generated by other threads, the model they use is not quite so refined. Instead it is kind of an ad-hoc implementation of the same idea, so instead of having a single event buffer, there are many. These buffers are not blocking like in the case of the login server how ever.
The old parts of the server are also frame-based, in that their main thread runs the logic in specified increments of time (FPS, frames per second). With an event queue the thread can sleep on we can remove some of the latency provided by the frame-based approach. To make timers based on delta-time still function correctly, we can simply calculate a sleep-time for the event_wait() function much like we would sleep during a frame if we were waiting for vsync in 3D program.
I'll be looking at converting the old programs to this model at some point in the distant future, unless I come across something better.
